Morphological analysis and POS tagging¶
Morphological analysis is the identification of the structure of morphemes and other linguistic units, such as root words, affixes, or parts of speech.
POS (part-of-speech) tagging is the process of marking up morphemes in a phrase, based on their definitions and contexts. For example.:
가방에 들어가신다 -> 가방/NNG + 에/JKM + 들어가/VV + 시/EPH + ㄴ다/EFN
Tagging with KoNLPy¶
In KoNLPy, there are several different options you can choose for POS tagging. All have the same input-output structure; the input is a phrase, and the output is a list of tagged morphemes.
For detailed usage instructions see the tag Package.
Comparison between tagging classes¶
Now, we do time and performation analysis for executing the pos method for each of the classes in the tag Package.
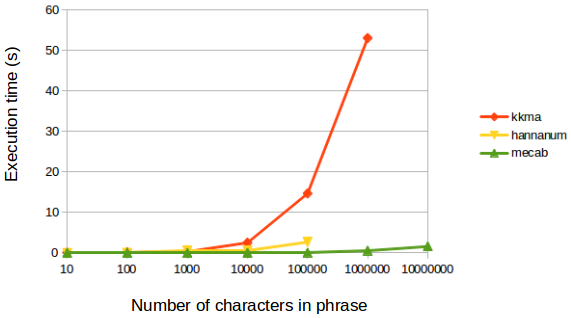
Performance analysis¶
The performance evaluation is replaced with result comparisons for several sample sentences.
“저는 대학생이구요. 소프트웨어 관련학과 입니다.”
“아버지가방에들어가신다”
“140823 Tofu Music Festival 존잘러에서 귀요미들로 변신ㅋㅋ #GOT7”
Kkma Hannanum Mecab 140823 / NR 140823 / N 140823 / SN Tofu / OL Tofu / F Tofu / SL Music / OL Music / F Music / SL Festival / OL Festival / F Festival / SL 존 / NNP 존잘러 / N 존 / VA+JX 잘 / MAG 잘 / VA 러 / NNP 러 / EC 에서 / JKM 에서 / J 에서 / JKB 귀요 / NNG 귀요미들 / N 귀요미 / NNG 미들 / NNG 들 / XSN 로 / JKM 로 / J 로 / JKB 변신 / NNG 변신ㅋㅋ / N 변신 / NNG ㅋㅋ / EMO ㅋㅋ / UNKNOWN # / SW #GOT7 / N # / SY GOT / OL GOT / SL 7 / NR 7 / SN
| [1] | All time analyses in this document were performed with time on a Thinkpad X1 Carbon (2013) and KoNLPy v0.3. |
| [2] | Average of five consecutive runs. |
| [3] | Average of ten consecutive runs. |
| [4] | The current Hannanum class raises a java.lang.ArrayIndexOutOfBoundsException: 10000 exception if the number of characters is too large. |

