Exploring a corpus¶
A corpus is a set of documents.
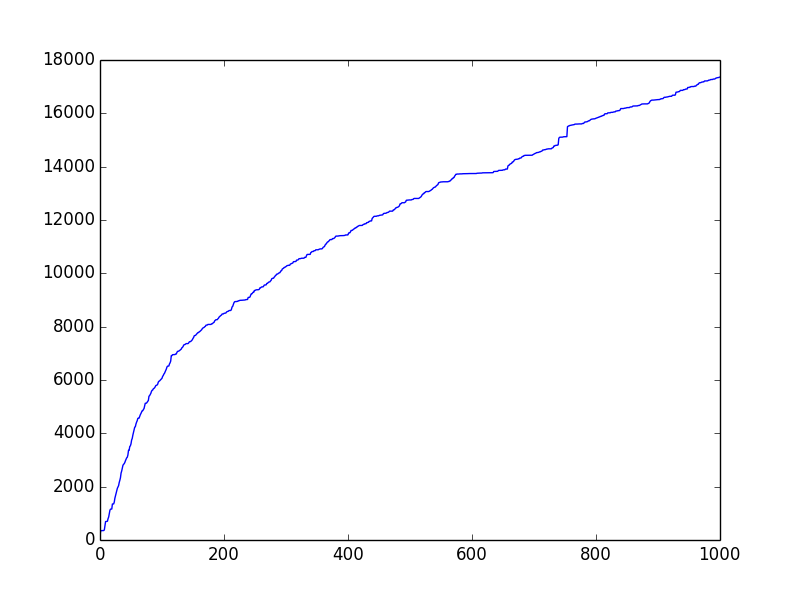
Below is a way of exploring unique tokens of a corpus, namely the Heap’s Law.
#! /usr/bin/python
# -*- coding: utf-8 -*-
from konlpy.corpus import kobill
from konlpy.tag import Twitter; t = Twitter()
from matplotlib import pyplot as plt
pos = lambda x: ['/'.join(p) for p in t.pos(x)]
docs = [kobill.open(i).read() for i in kobill.fileids()]
# get global unique token counts
global_unique = []
global_unique_cnt = []
for doc in docs:
tokens = pos(doc)
unique = set(tokens)
global_unique += list(unique)
global_unique = list(set(global_unique))
global_unique_cnt.append(len(global_unique))
print(len(unique), len(global_unique))
# draw heap
plt.plot(global_unique_cnt)
plt.savefig('heap.png')
- heap.png:
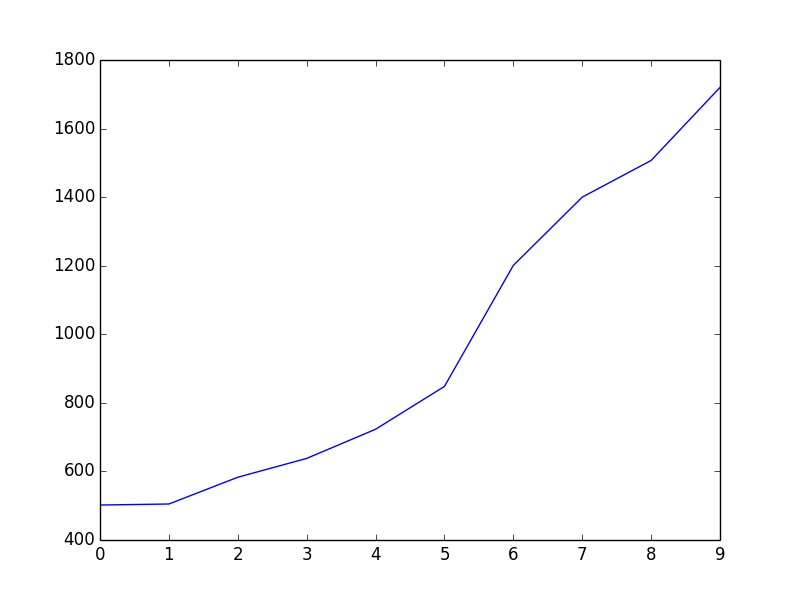
But why is our image not log-function shaped, as generally known? That is because the corpus we used is very small, and contains only 10 documents. To observe the Heap’s law’s log-function formatted curve, try experimenting with a larger corpus. Below is an image drawn from 1,000 Korean news articles. Of course, the curve will become smoother with a much larger corpus.
- heap-1000.png: